Embedded in a high dimensional space




Math talk
Tokenization. That's a new term for me. It’s the process of taking text data in whatever form you have it in and breaking it into smaller chunks called tokens. The model you use determines what these tokens look like.
Your mileage will vary across models but tokenization can generally be broken into two components:
- Take pre-processed data and convert it into text sentences
- Break those sentences into smaller chunks of words called tokens
I’m using the Transformers library from Hugging Face to access and build with large language models. After jumping through a few hoops, I managed to get approval from Meta to access all the Llama models. These models are open source, allowing me to access and change some of the underlying parameters (like weights and biases). Closed models, like Google Gemini and ChatGPT, don't allow you to make any changes to the model so you're stuck with what give and it's just a big black box. Additionally, open source is free where as the closed models charge for API access, often by the token. When you're a small hobbyist like me, it's far cheaper to go this route and pay for the occasional on demand GPU.
Each LLM has its strengths and weaknesses. I chose Llama because it's one of the best open-source models out there and has a robust support community. The code below uses AutoTokenizer from Hugging Face to declare which LLM to use for tokenization.
llama_3211b = "meta-llama/Llama-3.2-11B-Vision"
llama_3211b_tokenizer = AutoTokenizer.from_pretrained(llama_3211b)
....
tokenized_data = llama_3211b_tokenizer(batch_texts, return_tensors= "tf", truncation=True, padding=True)
tokenized_batches.append(tokenized_data)
After you setup the access, you take data from a typical structured table like this:
| release_date | artist_name | title | label_name | duration | genre_name | bpm | key_description | mix | is_remixed | is_remixer | mode | valence | danceability | energy | speechiness | loudness | liveness | instrumentalness | acousticness | isrc | artist_id | artist_url | track_id | track_url | label_id | label_url | genre_id | genre_url | key_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2022-06-24 | Preja | Movha | Supadjs Projects | 6:51 | Amapiano | 112.0 | Natural A Minor | Main | f | f | 0.0 | 0.367 | 0.732 | 0.492 | 0.2620 | -10.961 | 0.2970 | 0.00000 | 0.247000 | GBKQU2257859 | 1063851 | beatport.com/artist/preja/1063851 | 16636568 | beatport.com/track/movha/16636568 | 40460 | beatport.com/label/supadjs-projects/40460 | 98 | /genre/amapiano/98 | 8.0 |
| 1 | 2022-06-24 | Sidney Saige Ausama | Movha | Supadjs Projects | 6:51 | Amapiano | 112.0 | Natural A Minor | Main | f | f | 0.0 | 0.367 | 0.732 | 0.492 | 0.2620 | -10.961 | 0.2970 | 0.00000 | 0.247000 | GBKQU2257859 | 1063852 | beatport.com/artist/sidney-saige-ausama/1063852 | 16636568 | beatport.com/track/movha/16636568 | 40460 | beatport.com/label/supadjs-projects/40460 | 98 | /genre/amapiano/98 | 8.0 |
That data gets changed into a string representation, with each field and value being added from left to right.
text_values = (
"Track ID: 16636568, Title: Movha, Artist: Preja, Artist ID: 1063851, "
"Genre: Amapiano, Genre ID: 98, Label: Supadjs Projects, Label ID: 40460, "
"Release Date: 2022-06-24, Track URL: beatport.com/track/movha/16636568, "
"Mix: Main, Remix: No, Remixer: No, Duration: 6:51 minutes, BPM: 112.0, "
"Key ID: 8.0, Mode: 0.0, Valence: 0.367, Danceability: 0.732, Energy: 0.492, "
"Speechiness: 0.2620, Loudness: -10.961, Liveness: 0.2970, Instrumentalness: 0.00000, "
"Acousticness: 0.247000, ISRC: GBKQU2257859, Artist URL: beatport.com/artist/preja/1063851, "
"Label URL: beatport.com/label/supadjs-projects/40460, Genre URL: /genre/amapiano/98."
)
Show me the tokens
Feed that into the Llama tokenizer, and you'll get something like the output below—these are the tokens. A few things to note:
- The Ġ prefix is often added by LLMs like Llama to indicate that a token follows a space
- For example, ĠID means the word "ID" is preceded by a space
- Punctuation and numbers are treated as individual tokens
- URLs are often treated as single tokens or split into recognizable parts
tokens = [
'Track', 'ĠID', ':', 'Ġ16636568', ',', 'ĠTitle', ':', 'ĠMovha', ',',
'ĠArtist', ':', 'ĠPreja', ',', 'ĠArtist', 'ĠID', ':', 'Ġ1063851', ',',
'ĠGenre', ':', 'ĠAmapiano', ',', 'ĠGenre', 'ĠID', ':', 'Ġ98', ',',
'ĠLabel', ':', 'ĠSupadjs', 'ĠProjects', ',', 'ĠLabel', 'ĠID', ':', 'Ġ40460', ',',
'ĠRelease', 'ĠDate', ':', 'Ġ2022-06-24', ',',
'ĠTrack', 'ĠURL', ':', 'Ġbeatport.com/track/movha/16636568', ',',
'ĠMix', ':', 'ĠMain', ',', 'ĠRemix', ':', 'ĠNo', ',',
'ĠRemixer', ':', 'ĠNo', ',', 'ĠDuration', ':', 'Ġ6:51', 'Ġminutes', ',',
'ĠBPM', ':', 'Ġ112.0', ',', 'ĠKey', 'ĠID', ':', 'Ġ8.0', ',',
'ĠMode', ':', 'Ġ0.0', ',', 'ĠValence', ':', 'Ġ0.367', ',',
'ĠDanceability', ':', 'Ġ0.732', ',', 'ĠEnergy', ':', 'Ġ0.492', ',',
'ĠSpeechiness', ':', 'Ġ0.2620', ',', 'ĠLoudness', ':', 'Ġ-10.961', ',',
'ĠLiveness', ':', 'Ġ0.2970', ',', 'ĠInstrumentalness', ':', 'Ġ0.00000', ',',
'ĠAcousticness', ':', 'Ġ0.247000', ',', 'ĠISRC', ':', 'ĠGBKQU2257859', ',',
'ĠArtist', 'ĠURL', ':', 'Ġbeatport.com/artist/preja/1063851', ',',
'ĠLabel', 'ĠURL', ':', 'Ġbeatport.com/label/supadjs-projects/40460', ',',
'ĠGenre', 'ĠURL', ':', 'Ġ/genre/amapiano/98', '.'
]
The text tokens are transformed into embeddings—numeric representations of the tokens in a high-dimensional space. Each token is represented by a list of numbers called a vector, which can contain hundreds of values, depending on the model and embedding size. These vectors capture semantic information about the tokens, allowing the model to understand relationships between words, such as similarities in meaning and context.
embeddings = [
16042, 3110, 25, 220, 4645, 5245, 5313, 11, 11106, 25, 31048, 40961, 11,
29459, 25, 34248, 44027, 11, 29459, 3110, 25, 220, 6849, 20555,
# ..... removed a few rows to save space
11, 41395, 25, 76212, 611, 18682, 17829, 11, 41395, 3110, 25, 220, 975,
11, 916, 14, 1530, 38666, 351, 299, 1009, 1474, 11785, 14, 10132, 3174,
11, 41395, 5665, 25, 611, 34713, 45273, 2931, 6953, 752, 42357, 14, 975, 13
]
Click here to skip math
When I say "high-dimensional space," I mean that a 500-value vector exists in a space with 500 dimensions, with each value representing a specific position within those dimensions. In other words:

Pretty charts
Here are some charts I made. The first is a word cloud based on the bios of 55,000 artists, which I gathered by scraping Beatport. These artists are the ones who earned Beatport points over the past few years.
This is from some exploratory analysis I did on the data, which is also part of a final project I'm working on for school.
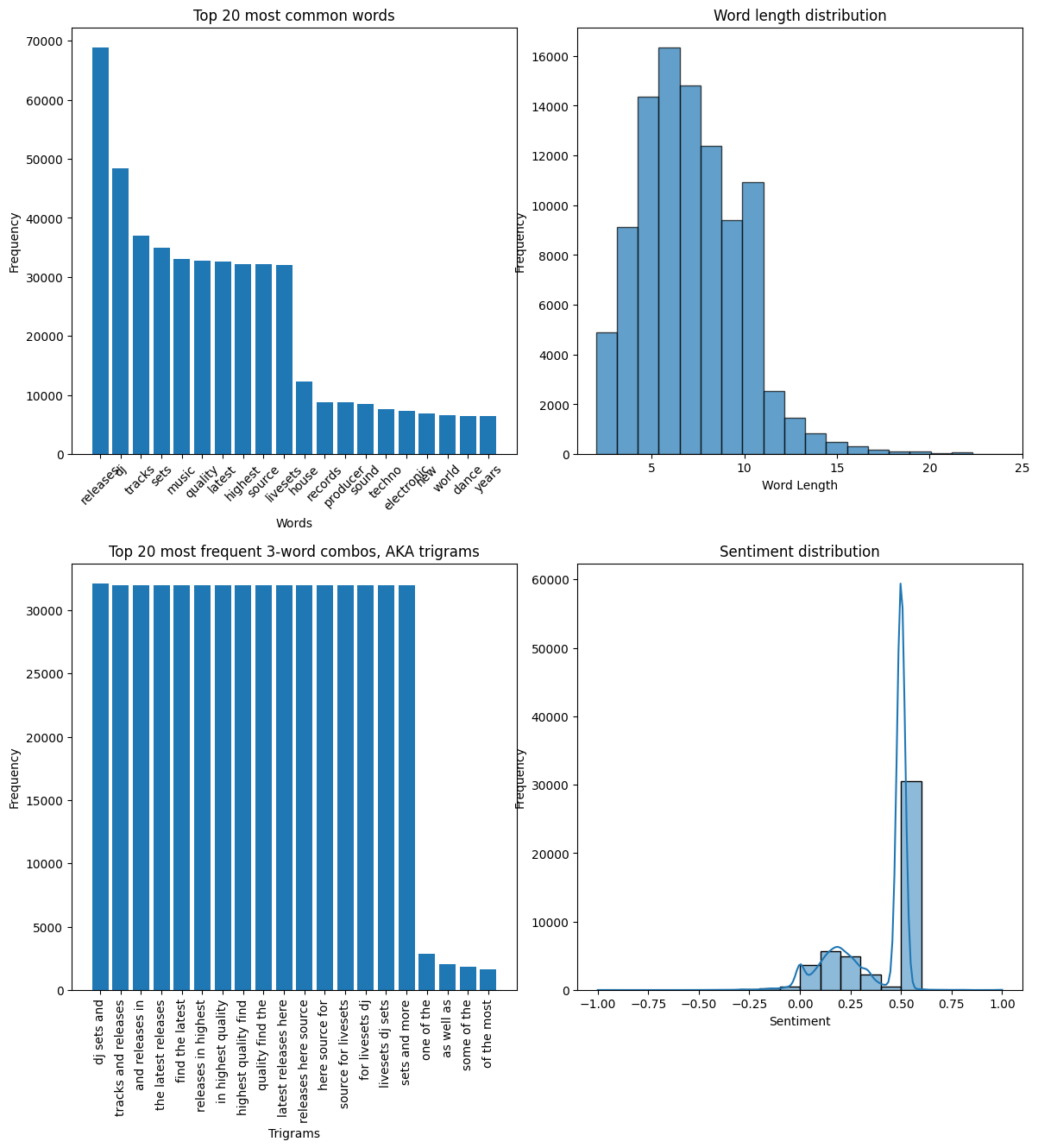
Top 20 most common words: I used Scikit-Learn to remove "stop words" (e.g., "and," "if," etc.) and then plotted the top 20 words by frequency across the bios.
Word length distributions: Exactly as it sounds—showing the distribution of word lengths.
Top 20 most frequent 3-word combos: Counts the most common three-word combinations and displays their frequencies. This is commonly called a "trigram."
Sentiment distribution: A scale from -1 to +1, representing most negative to most positive sentiment.
The future is now
Back in March, after I applied for grad school, I did some initial research and set a goal: By late fall, I wanted to fine-tune an open-source large language model using data that needed significant prep work. At the time, I didn’t know Python, nor did I understand much about how these models actually worked or the levers you could pull to adjust their behavior. Honestly, this website didn’t even exist back then.
Several months later, that goal is now within reach. Part one of Project Dolly Shield took me back to the start of my work with the Beatport and Spotify data I’ve been using. Preparing data for modeling is still the most time-consuming and crucial part of the process. You always end up revisiting and making changes, but at some point, the data is ready enough for the first big training push. I’m just about at that point with the data I have. I've also started on part two, which fixes some mistakes I made earlier and lays the groundwork for the training attempt.
The future is here. What are you waiting for?




