Getting to the root of the matter



It’s 6:15am on August 1st. Wait, it’s August 1st, right? Or is it still July? No, it’s definitely August. At work I’m working on some upcoming releases, which means the days get more and more intense. This isn’t unique to Disney, it’s part of the product manager career experience. When a release is coming up, you do everything in your power to get the product out the door. You plan user documentation, get bugs in front of the right engineering team, make sure the data model you’re referencing is the right one. But this is part of the rush, right? You’re gonna release some feature or update or whatever that you’ve been working on and lining up support or funding and now it’s time to go.
Anyway. So, there I was at 6:15am, trying to figure out some final code refactoring (“less bad”). I once again had a completely arbitrary deadline of August 1st to finish part two and I once again was determined to hit it. This is what we like to call masochism. With part one focusing heavily on using gradient descent to optimize the cost function of a single feature linear regression, part two really focused on getting scaling right and sharpening the skills around model evaluation. I knew, coming out of part one, I needed to find a non-straight line model to fit my data.
And, you know what? Back for an encore from high school math is our deal old friend: the polynomial. That’s right! Get those exponents flying around and you can make your model do all sorts of fun stuff. Now, strictly speaking, do I remember learning about polynomials in high school? No, no I do not. However, I wasn’t diagnosed with severe ADHD until I was 30 and that…would explain a lot of things. I’m almost certain, in the defense of math teachers around the world, I was present in a room where polynomials were discussed.

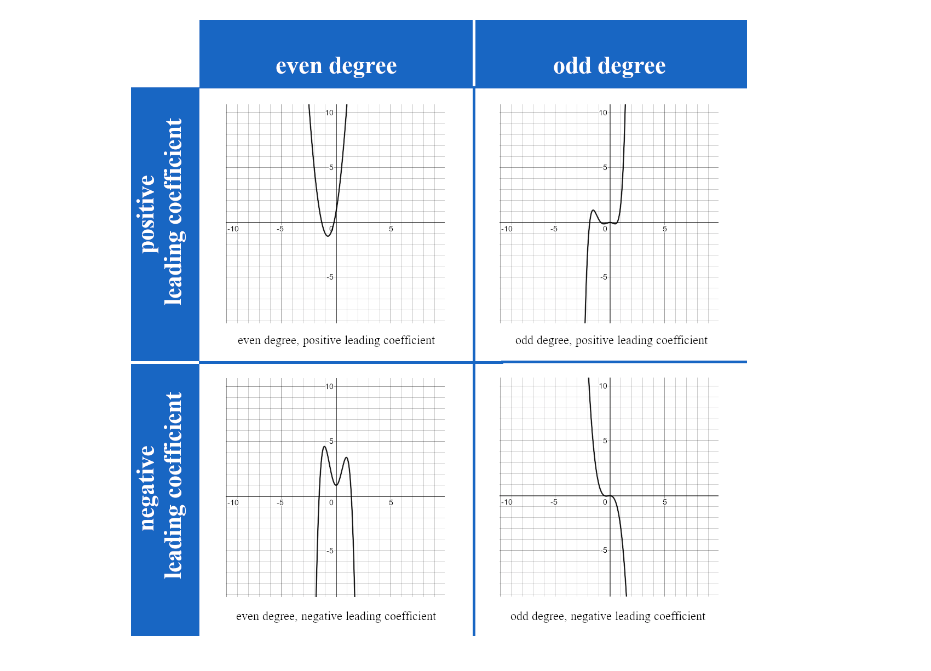
As part of the Johns Hopkins Algebra Specialization on Coursersa that I finished earlier this year, I had to (re)learn polynomials and, oh boy, it was a hot mess. This right here is pulled right from the lecture notes. Are you with me? If the first number you hit is positive and that first exponent is even, top left. It’s giving whatever Brat summer means. Same setup, just with an odd exponent? Top right. If the first number is negative and that first exponent is even, bottom left. Vibe shift in a really bad way? Bottom right.
After I finished that section, I remember thinking “well hopefully I won’t have to deal with polynomials again.” Which: lol. Here we are, running a machine learning model that uses polynomials. Needing a polynomial function to rescue me.
As you move from the shallow end to the sorta less shallowish part of the machine learning pool, you start to hear a lot of the same terms very often: underfit, high bias, overfit, variance, generalization. When you put your data through the poly regress Rube Goldberg machine, you can plot out the cost values for the different polynomial degrees. Generally speaking: the more degrees, the better your training data will perform. However because math is cruel sometimes, there comes a point where higher degrees means your model isn’t generalizing well, causing high variance. Variance here is the difference between what the model did on training data versus what it did on validation data.
For your model to generalize well, which means it can be used by real people in the real world, you need to find the balance between the two costs. Generalization is what would let you put a prediction tool on your website for the cost of a new bike or some new kit. You’ve trained the model and know it can handle data it hasn’t seen.
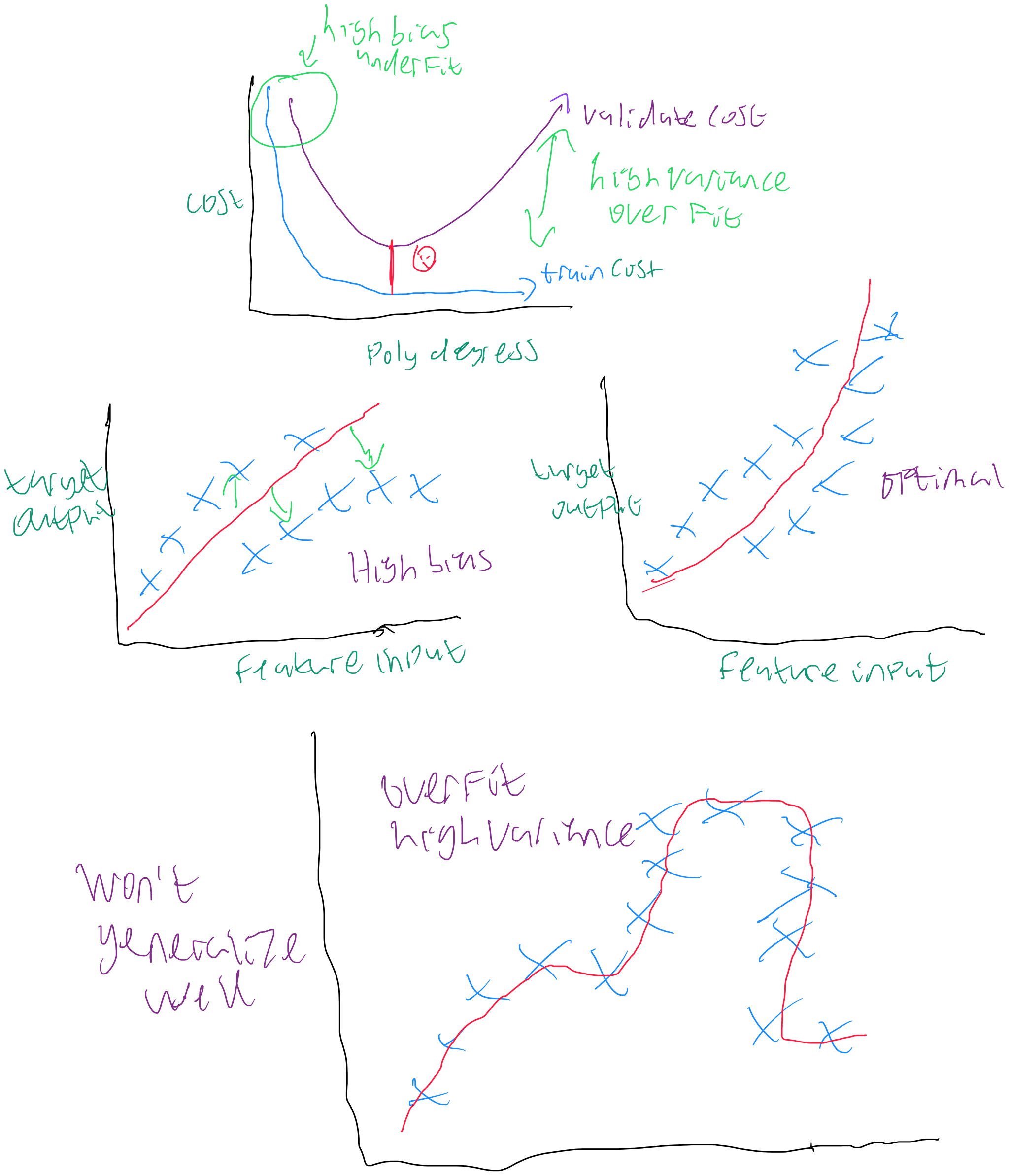
That chart at the top is what the cost curves should look like. You’ll never believe what happened next when I went to do mine:
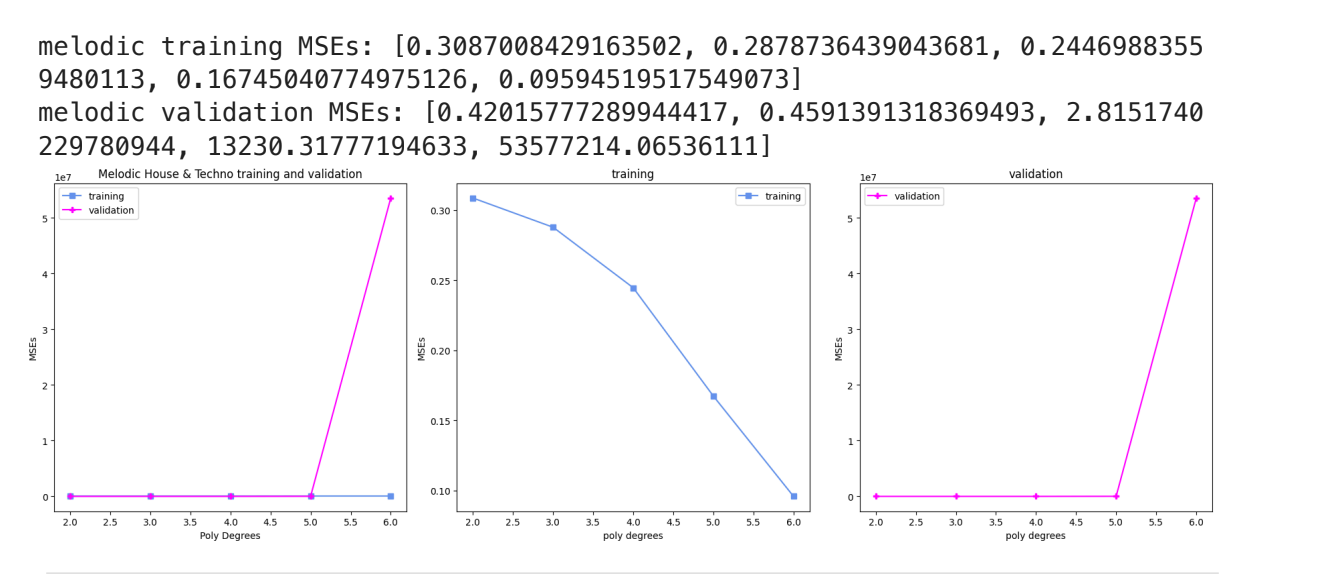
The validation data was vibing and then it wasn’t and it, and this is the official term, went the fuck off. Training data is like gurl, I’m trying to behave, can you not? and validation was like hold my phone, I gotta be Brat af. You put the lime in the coconut, stupid.
But for real for real, these fits aren’t actually that bad. They’re not kings but they’re also not degenerate royals. They’re like the Princess Anne of the models. Those charts along the top are shaded by density and, surprise! It’s all very dark blue. In part 3, I’m going to use logistic regression, ReLu, and other techniques to try and slice this data up. IE - if I separate this out by top 10% versus bottom 90%, how would that do? There are those long tails on a lot of the charts and I want to see if there’s something there.
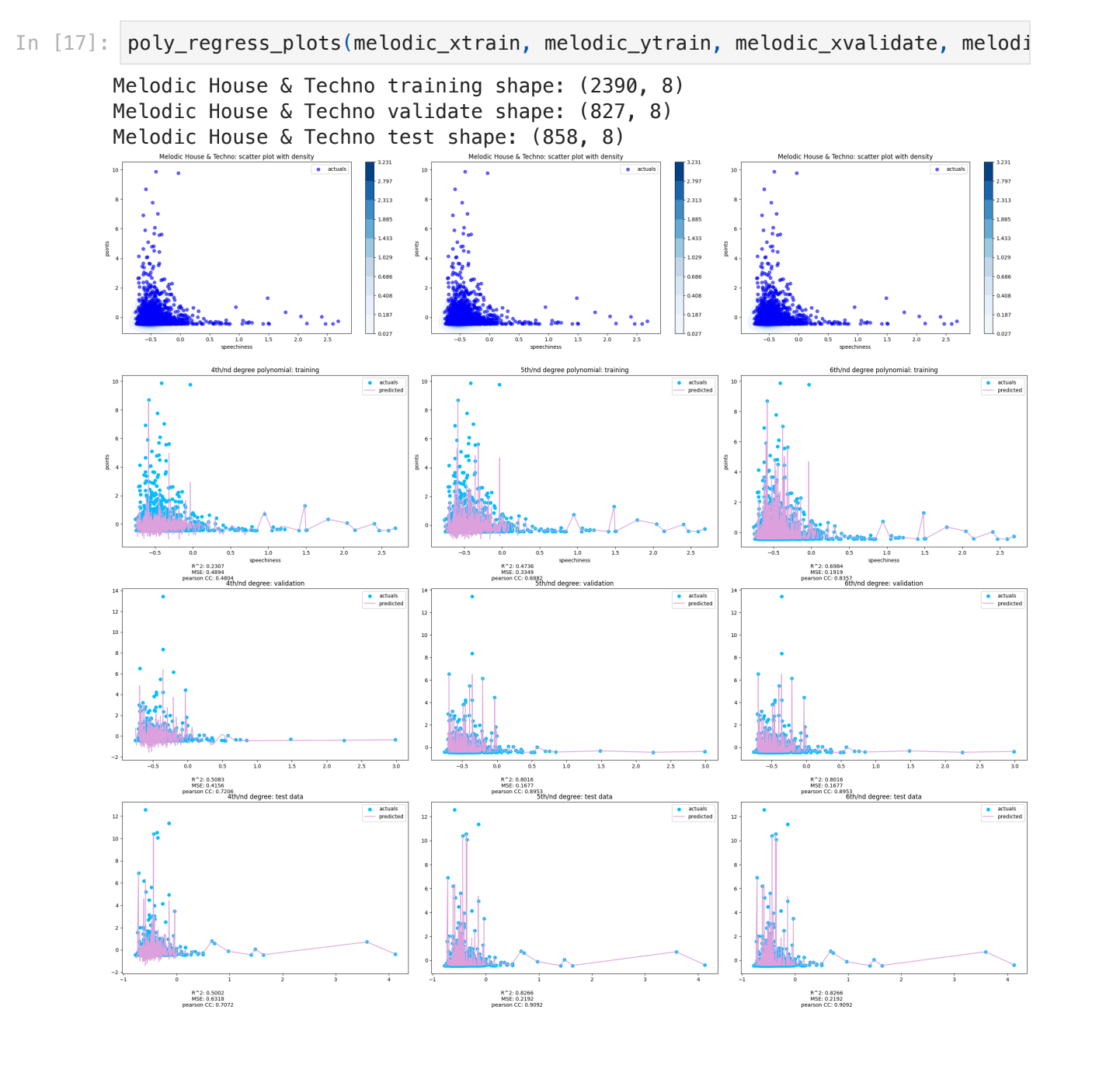
Some of this is overfitting. There’s a spike in stats for the 4th degree (middle column) from training to validate and test. But, overall, this is not too bad. With the single input linear regression from part one, there weren’t many follow ups around where to focus, just a lot of were not. A lot of skills were picked up and a lot of things were ruled out but no oh, this is good moment. With the above charts and others I have in the public Notebook, I’m starting to see relationship emerge that I can dig into.
What’s next
I have about one more month where I can focus exclusively on my passion projects, after which I start grad school. I feel confident I’m going to get a basic 1-2 layer neural network with 2-3 target outputs done in the next few years. I do want to start learning about natural language processing because I have news stories about electronic music artists that I want to use to help paint a more holistic picture.
Additionally, I want to get away from the points target output I’ve been using because I only have that metric for a small subset of songs. I know the smarty pants in the back are saying “you can probably guess the rest based on the data!” I hear you. I want to get my hands fully around the density and skewness first because assigning points out to all the other songs is going to really hit the bottom hard and exacerbate that problem. There’s a there, there but I’m still working on that puzzle.
Finally, I do have a stretch goal to start my own small fine tuning training of Meta’s Llama 3 model. I set this back in March to try and start something in the fall and I just might have the right pieces done.
Part 3, coming sometime in August, will cover some basics from the Tensor Flow neural network world and then…we will see how grad school is going.




