Project Dolly Shield Overview
The future is here, and you're just in time

Latest work
Project Dolly Shield, Reborn: Using LLMs to Improve Enterprise Data Architecture Frameworks
This is my masters thesis research proposal, a labor of love.

Project Dolly Shield, Chapter 1, Part 2: The Road to Tokenization is Long and Involves Better Infrastructure
It’s time for everyone’s favorite topic: data infrastructure

Project Dolly Shield, Chapter 1, Part 1: The Road to Tokenization
Technical overview of chapter 1, part 1 of Project Dolly Shield

Embedded in a high dimensional space
Thoughts on chapter 1, part 1 of Project Dolly Shield

Overview
Dolly is the name of a sheep furniture fixture we have in our home. Mao-Lin bought it for $1,500 dollars before he met me and named her Dolly, after the famous cloned sheep from the 90’s.
When he first explained this to me, I remember thinking to myself “well OK, that’s def weird, but sure.” Dolly has since grown into one of my favorite things in our home and I would do anything to protect her. Additionally, Dolly is famous amongst my fitness friends because Dolly had to be moved from the bedroom to the living room to make space for my Peloton when I moved in.
Project Dolly Shield is named in her honor.
Cool story, bro, but what's going on here?

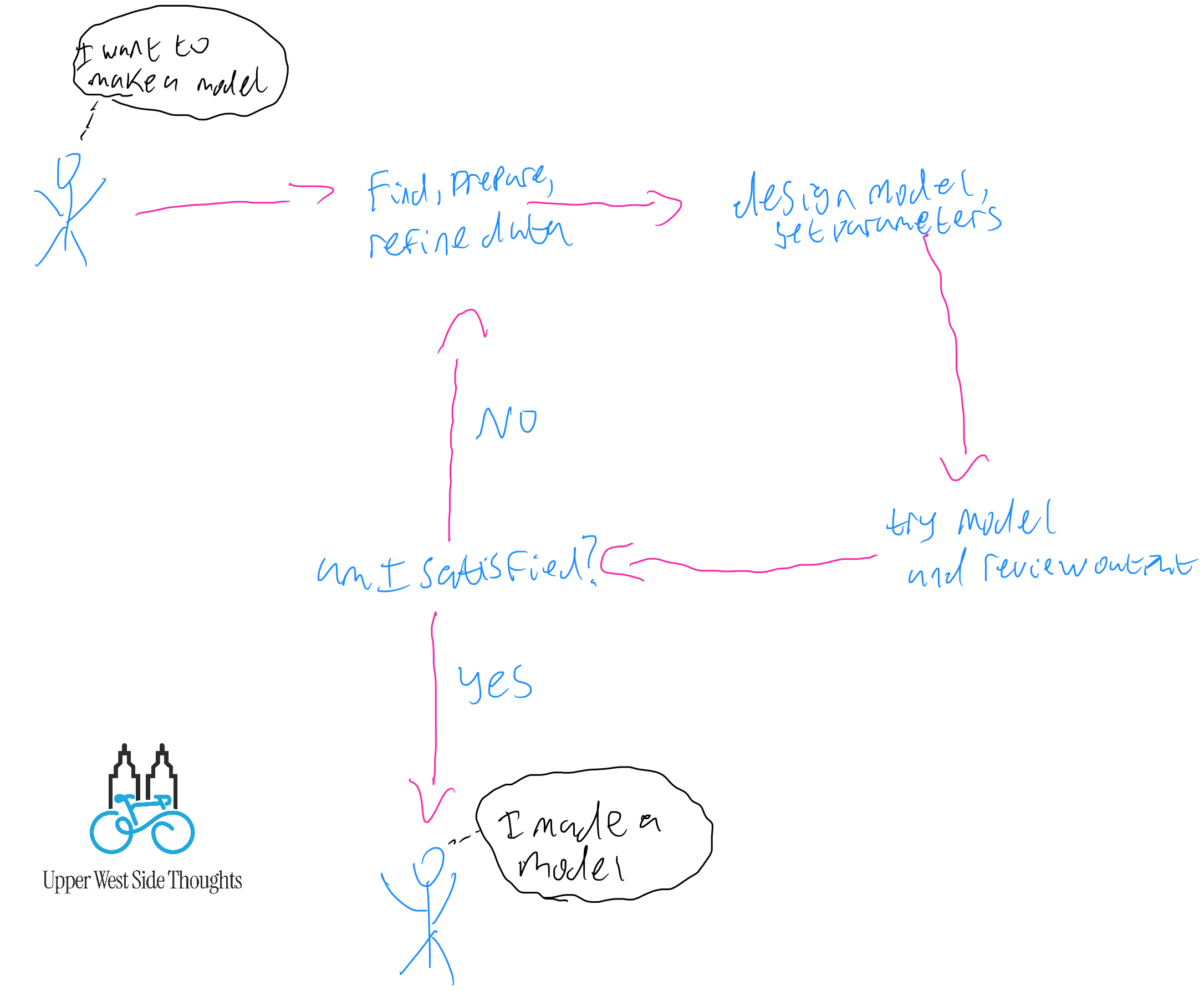
Here's a drawing to set the scene: